
🧠 OpenAI Just Released GPT‑OSS
Their First Open-Weight Models in Years, what does it mean?

OpenAI has made a major move in the AI space. On August 5, 2025, they released GPT‑OSS, their first open-weight language models since GPT‑2. With two models, gpt‑oss‑120b and gpt‑oss‑20b, OpenAI is giving developers and researchers the ability to download, inspect, fine-tune, and run state-of-the-art models entirely on their own hardware.
This release signals a big shift toward transparency and local control over high-performing AI models.
🔍 What Are These Models?
gpt‑oss‑120b
A large Mixture-of-Experts (MoE) model with 117 billion total parameters (5.1 billion active per token). It is designed for enterprise-level hardware such as NVIDIA H100s or similar data center GPUs. Despite its size, it performs similarly to OpenAI’s o4-mini model on core reasoning benchmarks like MMLU, AIME, and HealthBench.gpt‑oss‑20b
A smaller, more efficient version with 21 billion total parameters (3.6 billion active per token). It can run on 16 GB desktop GPUs or even newer Snapdragon-powered Windows laptops. Performance is comparable to o3-mini in reasoning and STEM-related benchmarks.
Both models are released under an Apache 2.0 license. They support chain-of-thought reasoning, flexible fine-tuning, and basic tool use. You can use them through platforms such as Hugging Face, Azure AI Foundry, AWS Bedrock, Ollama, and others.
⚙️ Under the Hood: Architecture and Features
These models are built using Mixture-of-Experts architecture:
gpt‑oss‑120b uses 36 layers and 128 experts per layer, activating 4 experts per token. It supports a context window of up to 128,000 tokens. This configuration delivers strong reasoning with more efficient compute for large tasks.
gpt‑oss‑20b has 32 experts total, with 4 active per token. It's optimized for lighter environments and can run locally on standard consumer hardware.
Both models were trained using supervised fine-tuning and reinforcement learning from human feedback. Developers can adjust reasoning behavior using system messages to balance speed and accuracy.
🛡️ Safety and Preparedness
Before releasing gpt‑oss‑120b, OpenAI tested adversarially fine-tuned versions using their Preparedness Framework. They assessed biosecurity, cyber-risk, and potential misuse. The result: even under aggressive tuning, the model did not demonstrate high-risk capabilities.
OpenAI determined that these models pose no greater risk than current open-source alternatives. Still, they will continue to monitor emerging risks and behaviors.
🚀 Why GPT‑OSS Matters
1. It’s Truly Open
This is the first time OpenAI has released open weights since GPT‑2. Developers now have full access to modern, high-performing language models without needing to rely on an API.
2. You Can Run It Anywhere
From enterprise GPUs to consumer laptops, these models are optimized for deployment across a wide range of environments. You’re no longer locked into the cloud or proprietary ecosystems.
3. Competitive Benchmark Results
Despite being open-weight, both models deliver top-tier performance on reasoning and STEM benchmarks. gpt‑oss‑120b is especially capable, rivaling o4-mini on several metrics.
4. Designed for the Real World
Support for tool use, high context windows, and efficient expert activation makes these models practical for real applications—whether it’s agent development, customer support, or research assistance.
🧰 Ideal Use Cases
AI assistant development
Build advanced agents that reason, plan, and execute tasks using local tools, without API costs.Private fine-tuning
Train and customize models securely on private datasets without sending data to the cloud.Edge deployment
With gpt‑oss‑20b, you can run high-quality language models on phones, laptops, and even embedded systems.
📊 How Does GPT‑OSS Compare to o3 and o4?
While GPT‑OSS isn’t positioned as a flagship like o3 or o4, its performance lands surprisingly close — especially for open-weight models.
Let’s break it down:
gpt‑oss‑120b vs. o4-mini
On major benchmarks like MMLU, AIME, and GPQA, gpt‑oss‑120b scores are in the same ballpark as o4-mini. That means strong performance on reasoning, math, and science — even without the proprietary data or toolchain that o4 benefits from inside ChatGPT.gpt‑oss‑20b vs. o3-mini
The smaller 20b model compares well to o3-mini, especially in constrained environments. It's optimized for lower compute usage and still handles basic chain-of-thought reasoning and vision-based tasks (with some customization).No built-in tool use (yet)
Unlike o3, which comes with native tool integrations inside ChatGPT (Python, browser, DALL·E, etc.), GPT‑OSS doesn’t ship with these baked in. But since it supports long context and chain-of-thought, you can build tool usage logic on top — it just takes a bit more engineering.Context length parity
Both GPT‑OSS models support up to 128K tokens — putting them ahead of o3-mini and on par with newer variants of o4-mini and o3. This is a big deal for document-heavy applications, summarization, and reasoning across long threads.Inference speed and cost
On a per-token cost basis, gpt‑oss-20b and 120b can be significantly cheaper to run — especially when hosted locally. If you’re deploying at scale and optimizing for cost-efficiency, OSS models may beat out o3 or o4 through control alone.
In short: While o3 and o4 are still top-tier when it comes to seamless user experience and tool orchestration, GPT‑OSS gives you comparable raw performance with full control, open weights, and no API ceiling. It’s the first time we’ve seen this level of capability opened up for builders outside the walls of a closed lab.
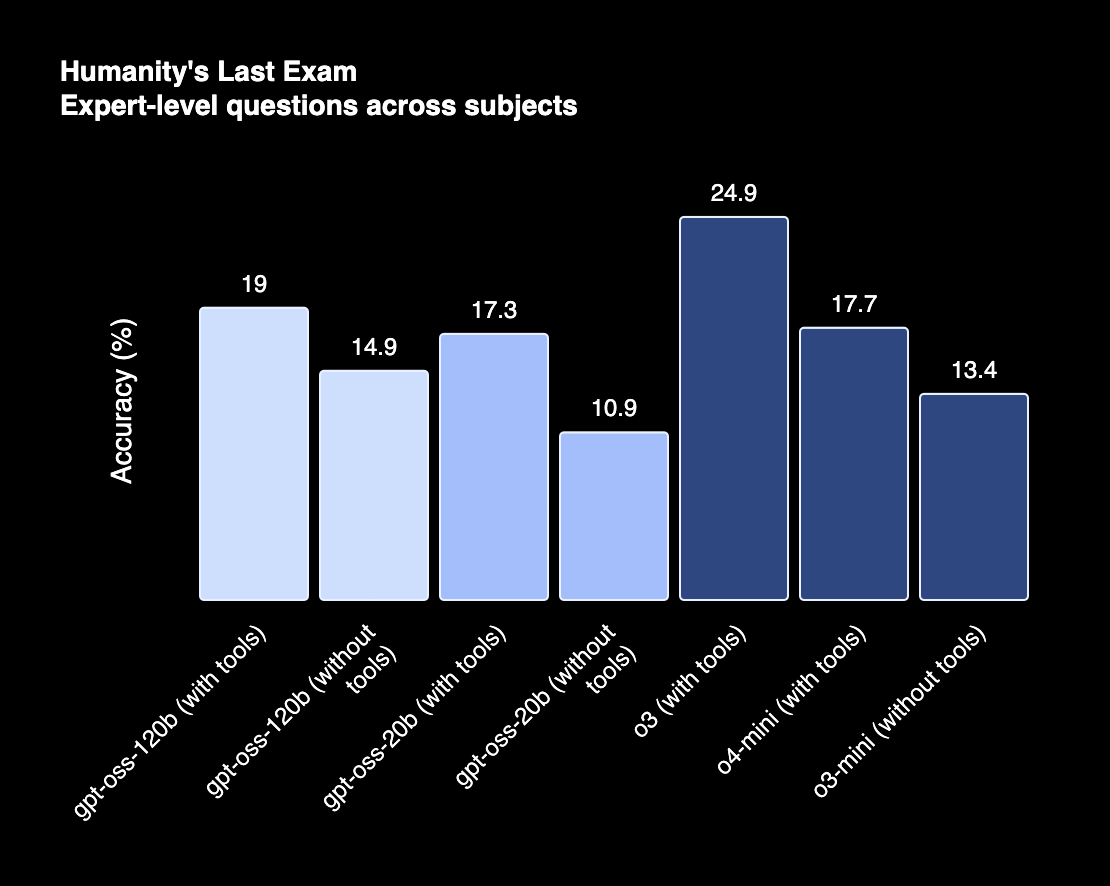
Full results here
🧵 Final Thoughts
GPT‑OSS is a landmark moment for developers and researchers. While it doesn’t come with the fanfare of GPT‑5, this release gives you complete access to high-performing models that you can run, inspect, and extend on your own terms.
Whether you're building the next AI tool or just exploring what’s possible, now is the time to dive in. These models offer transparency, control, and power that can drive the next generation of applications forward.
—
📨 Enjoyed this post?
Subscribe to AI Pulse Weekly for hands-on insights, model breakdowns, dev tools, and emerging AI trends.